DB 모델링
1. 데이터 모델링
업무보다는 데이터를 중심으로 모델링을 진행하는 방법
일반적으로 개념적 모델링, 논리적 모델링, 물리적 모델링으로 분류된다.
-
2. 개념적 모델링
요구분석 단계에서 정의된 핵심 개체와 그들 간의 관계를 바탕으로 ERD를 생성하는 단계
* ERD: Entity Relation Diagram 엔티티들의 관계를 도형으로 표현한 것
- 주요 용어들
엔티티(Entity)
실제로 관리해야 할 구체적인 대상
어떠한 객체 뿐만 아니라 작업들도 엔티티로 만들 수 있음
속성(Attribute)
엔티티가 가지고 있는 특징
엔티티들을 더이상 분리할 수 없는 최소 단위와 같음
주 식별자
엔티티에 있는 데이터들을 서로 구분해 줄 수 있는 속성을 의미
주 식별자의 값은 다른 값들과 중복되면 안됨 (기본 키라고 생각)
값이 반드시 존재해야 하며, 주 식별자는 하나만 가지고 있어야 함.
보조 식별자
주 식별자를 대체할 수 있는 또 다른 속성
외래 식별자
엔티티와의 관계를 연결해 주는 식별자
관계를 만들어줄 때 사용하는 것
값이 존재하지 않을 수도 있으나 관계를 맺는 엔티티의 주 식별자나 보조 식별자와 연결되어야 함 (외래키로 사용)
관계
엔티티와 엔티티 간의 관계
반드시 있어야 하는 관계는 실선, 선택적은 점선
일대일 관계 (1:1, One To One)
A 엔티티에 존재하는 1건의 데이터와 대응되는 엔티티의 데이터도 1건일 경우
(노란 키는 주 식별자, 핑크 키는 외래 식별자)
일대다 관계 (1:M, One To Many)
A 엔티티에 존재하는 1건의 데이터와 대응되는 B 엔티티의 데이터가 여러 건일 경우
EX) 학과 번호 (1) 마다 여러 학생 (M) 들이 대응됨, 학과명(1) 마다 여러 학생(M)들이 대응됨
다대다 관계 (M:M Many To Many)
A 엔티티에 존재하는 여러 건의 데이터와 대응되는 B 엔티티의 데이터가 여러 건일 경우
다대다 관계는 직접 연결하지 않고 교차 엔티티라는 것을 추가로 연결되어 있음
그래서 일대다 - 일대다 관계로 이어짐 (1:n - m:1)
교차 엔티티의 키 색깔이 다르다.
식별 관계를 이해해야 구분할 수 있다.
EX) 하나의 학생은 여러 과목(M)을 들을 수 있고, 과목은 여러 학생(M)들이 들을 수 있음
식별, 비 식별 관계
식별 관계는 부모 엔티티의 주 식별자를 자식 엔티티의 주 식별자, 외래 식별자로 사용하는 관계
비 식별관계는 부모 엔티티의 주 식별자를 자식 엔티티의 외래 식별자로만 사용하는 관계
-
ERD CLOUD 사용해 보기
erdcloud.com 접속 후 간단한 것을 만들어보자.
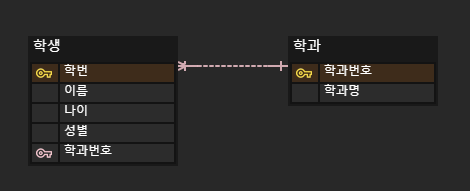
위와 같이 간단한 엔티티를 만들어서 연결해 주었다.
학생에서는 학번이 주 식별자, 학과에서는 학과번호가 주 식별자가 된다.

한 과목에 여러 학생이 들을 수 있고, 한 학생이 여러 과목을 들을 수 있기 때문에
학생과 과목은 다대다 관계가 될 수 있다.
다대다 관계를 완성하기 위해 교차 엔티티를 수강신청이라는 이름으로 생성하였다.
또한, 다대다 관계에서 식별 관계를 주어 과목번호와 학번 속성을 묶어서 주 식별자로 만들었다.
이 둘은 주 식별자와 동시에 외래 식별자의 역할(다른 엔티티를 참조함)도 한다.

이번에는 비 식별관계로 만들었다.
수강신청 엔티티에 따로 주 식별자 키가 존재한다.
연습을 위해서 SQL문 연습 시에 사용했던 테이블을 참조하여 ERD를 그려보았다.

부서는 여러 사원을 가질 수 있고, 사원은 하나의 부서를 가질 수 있어서 일대다 관계로 연결해 주었다.
하나의 직급에는 여러 사원이 존재하고, 사원은 하나의 직급을 가질 수 있어서 일대다 관계로 연결해 주었다.
이렇게 연결해 주었기 때문에 테이블을 조회했을 때 employee 테이블에 부서 코드와 직급 코드가 존재하는 것이다!
-
3. 논리적 모델링
개념적 모델링 과정에서 추상화된 데이터를 구체화하여 개체, 속성을 테이블 화하고 상세화 하는 과정
3.1 이상 (Anomaly)
정규화를 진행하지 않은 엔티티를 대상으로 삽입, 갱신, 삭제 시 발생할 수 있는 예기치 못한 현상
삽입 이상, 갱신 이상, 삭제 이상이 있다.
이러한 이상 과정들을 줄이기 위해서 진행하는 것이 정규화이다.
3.2 제 1정규화
하나의 속성이 하나의 값을 갖도록 한다.
3.3 제 2정규화
(제 1정규화를 만족하면서) 주 식별자 전체에 종속적이지 않는 속성을 분리한다.
(주 식별자가 복합 식별자일 경우에 해당)
성적은 학번, 강의 이름에 종속적임
강의실은 강의이름에 종속됨..
이걸 오른쪽 표처럼 분리 해 낼 수 있음
3.4 제 3정규화
주 식별자에 종속적이지 않고 다른 속성에 종속적인 속성을 분리한다.
정규화에 대해서는 너무 어렵게 생각하지 말자!
하다 보면 자연스럽게 될 것 ㅠ.ㅜ
-
4. 물리적 모델링
논리적 모델링 과정에서 표현된 데이터를 실제 데이터베이스에 맞도록 구현하는 과정
논리적 DB 설계 | 물리적 DB 설계
엔티티 테이블
속성 컬럼
주식별자 기본키
외래식별자 외래키
. . .
즉,
속성 -> 컬럼
주 식별자 -> PRIMARY KEY
보조 식별자 -> UNIQUE KEY
외부 식별자 -> FOREIGN KEY
+ 추가로 필요한 객체(뷰, 인덱스 등) 생성
-
ERD CLOUD에서
로지컬 뷰는 논리적 모델링까지의 내용을 보여준다.
피지컬 뷰는 물리적 모델링을 통해서 내용을 설정한 것을 보여준다.
아래는 아까 위 예시에서 설정해 본 것이다.
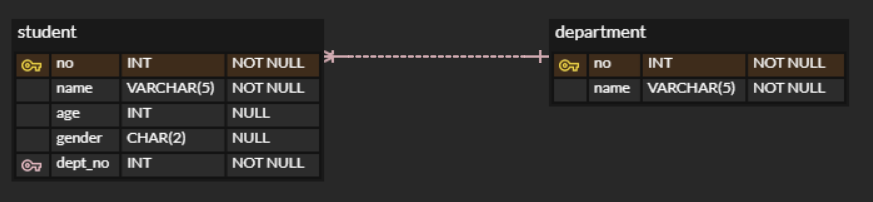
ERD CLOUD 사용 시에
도메인은 속성 값의 범위를 지정해 주는 것
타입은 열의 데이터 타입
Allow NULL은 NULL 값 여부
Default Value는 값이 들어오지 않으면 정해줄 기본 값
Comment 열에 대한 설명을 적는 것으로
위 예시에서는 간단히 타입, 널 여부만 보이도록 하였다.
-
반 정규화
이름 그대로 정규화의 반대
정규화를 너무 세심하게 하면 엔티티가 계속해서 나눠진다.
데이터를 저장할 때 여러 테이블을 사용하겠지만
읽어올 때 여러 테이블을 조인해서 가져와야 하기 때문에 성능에 좋지 못할 수 있다.
그렇기 때문에 A 테이블과 B 테이블이 있을 때 두 테이블을 따로 분리해도 되고
합쳐도 되는 상황이라면 분리하는 것보다 합치는 것이 성능에 더 좋을 수 있다.
* 반 정규화 시에는 다른 테이블에 영향을 미치는 지도 꼭 확인해 본 뒤 진행 해야 한다. 이상 현상이 발생할 수 있기 때문.
테이블
테이블
데이터베이스에서 데이터를 저장할 수 있는 핵심이 되는 개체로 행과 열로 구성되어 있다.
모델링한 결과를 가지고 테이블을 생성한다.
-
테이블 생성
CREATE TABLE 구문 사용
DEFAULT는 값을 입력하지 않았을 때 자동으로 입력되는 기본 값을 정의하는 방법이다.
NULL 값을 허용하려면 NULL을, 허용하지 않으려면 NOT NULL을 사용하면 된다.
되도록이면 영어를 사용해서 지어주도록 하자.
CREATE TABLE 테이블명 (
열이름1 타입 NULL 값 여부,
열이름2 타입 NULL 값 여부,
...
열이름N 타입 DEFAULT 디폴트값
);
NULL 값 여부를 입력하지 않는다면, NULL 값을 허용한다. (기본임)
테이블 내 열 값은 동일한 이름을 가질 수 없다.
타입 다음에 DEFAULT 값을 적어주면 된다.
해당 열에 값을 입력하지 않으면 DEFAULT 값을 대신 지정한다.
간단히 테이블을 하나 만들어보았다.
CREATE TABLE tb_number (
mem_no INT,
mem_id VARCHAR(20),
mem_pass VARCHAR(20),
mem_name VARCHAR(15),
enroll_date DATE DEFAULT CURDATE()
);
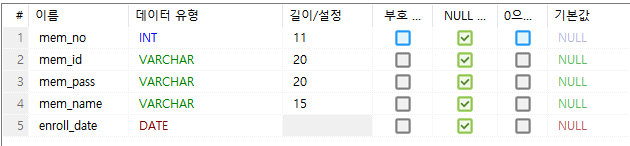
생성된 테이블 값에 따로 NULL 값 허용 유무를 적용해주지 않아서
테이블 정보를 살펴보면 NULL 값을 허용하게 설정되어 있다. (기본값)
샘플 데이터를 추가해 보자.
INSERT INTO tb_member VALUES (1, 'user1', '1234', '홍길동', '2022-11-09');
INSERT INTO tb_member VALUES (2, 'user2', '1234', '이몽룡', CURDATE());
INSERT INTO tb_member VALUES (3, 'user3', '1234', '성춘향', DEFAULT);
INSERT INTO tb_member(mem_no, mem_id) VALUES (4, 'user4');
2번째 줄은 DEFAULT 값을 가져온 것이 아니라,
바로 CURDATE() 값을 넣어준 것이다.
DEFAULT 값을 지정할 때, 3번째 줄처럼 DEFAULT라고 작성해주어야 한다.
DEFAULT 값인데 삽입할 때 비워도 되는 거 아닌가요?
> 이 경우에는 4번째 줄 SQL문처럼 작성해주어야 한다.
1-3번째 줄의 경우에는 열을 지정해주지 않았기 때문에 모든 열에 대해서 삽입하는 것이기 때문이다.
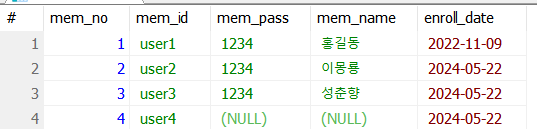
아래와 같이 추가된 것을 볼 수 있다.
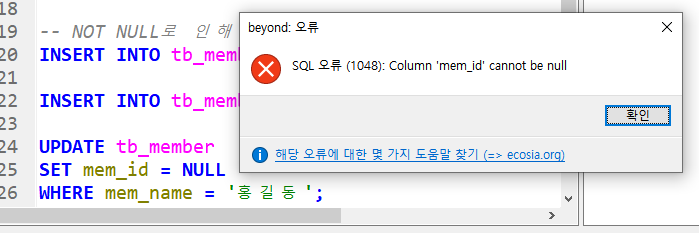
단, 4번째 줄의 SQL문의 경우, 테이블 생성 시에 NULL 값 허용을 하지 않았다면
SQL문을 실행했을 때 값이 에러가 난다.
또한, NULL 값 허용이 되어 있지 않은 경우에
TABLE 내 데이터 값을 수정하려고 할 때도 에러가 발생한다.
-
제약 조건
데이터의 무결성을 지키기 위한 제한된 조건을 의미
즉, 특정 데이터를 입력할 때 무조건적으로 입력되는 것이 아닌, 어떠한 조건을 만족했을 때 입력되도록 제약한다.
테이블 생성 시 제약조건을 설정할 수 있고 ALTER 구문을 통해서 제약조건을 설정, 변경, 삭제할 수 있다.
PRIMARY KEY 제약 조건
테이블에 존재하는 많은 행의 데이터를 구분할 수 있는 식별자를 기본 키(Primary Key)라고 부른다.
PRIMARY KEY 제약 조건은 기본 키로 사용할 열에 부여하는 제약 조건이다.
기본 키에 입력되는 값은 중복될 수 없으며, NULL 값이 입력될 수 없다.
* 테이블 당 기본 키는 하나만 설정할 수 있음.
대신에 여러 열을 묶어서 하나의 기본 키로 만들 수는 있음
-
UNIQUE 제약 조건
열에 중복되지 않은 유일한 값을 입력해야 하는 조건
* 중복되면 안 되지만 기본 키로 쓰지 않을 때
* PRIMARY KEY와의 차이점은 NULL 값이 입력 돼도 됨
PRIMARY KEY와 UNIQUE 가 생성 될 때 인덱스가 자동으로 생성된다.
(인덱스 내용은 나중에.. 검색 성능을 높이기 위한 DB 개체라고만 알아두자)
PRIMARY KEY와 UNIQUE 제약 조건을 주고 테이블을 다시 만들어보자!
DROP TABLE tb_member;
CREATE TABLE tb_member (
mem_no INT PRIMARY KEY,
mem_id VARCHAR(20) NOT NULL UNIQUE,
mem_pass VARCHAR(20) NOT NULL,
mem_name VARCHAR(15) NOT NULL,
enroll_date DATE DEFAULT CURDATE()
);
이 경우에 mem_no과 mem_id에 데이터 삽입 시 중복되지 않는 값을 넣어줘야 하며, NULL 값이 존재할 수 없다.
만약 새 데이터를 삽입할 때 PRIMARY KEY 값과 중복된 값이 존재하거나, NULL 값을 가지면 에러가 발생한다.
또한, UNIQUE 제약을 걸어준 mem_id 값에도 중복되는 값을 넣어주면 에러가 발생한다.
* PRIMARY KEY 지정 시 조건에 NOT NULL 이 포함되기 때문에 적어주지 않아도 된다.
mem_no과 같은 임의의 숫자로 만들어진 관련 없는 대리 키를 PRIMARY KEY로 지정하는 경우가 흔하며, 이 방법을 권장한다.

노란 키는 기본 키, UNIQUE 제약 조건이 붙었을 때는 빨간 키로 뜬다.
UNIQUE 값을 대체 키라고 부르기도 한다.
-
여기서 mem_no 값은 1씩 늘어나고 있는데 이 값을 생성될 때마다 자동으로 기본 키 생성 & 증가하도록 설정해 보겠다.
(생략) ..
mem_no INT AUTO_INCREMENT PRIMARY KEY,
...(생략)
AUTO_INCREMENT 부분을 입력해 준다.
1부터 1씩 증가하는 숫자값을 넣어주기 때문에 반드시 데이터 형태는 숫자 형태이어야만 한다.
이 값은 자동으로 입력해 주기 때문에 새 데이터를 삽입할 때 없다고 생각하고 다른 값만 삽입하면 된다.

위와 같이 입력해 주었을 때, mem_no 값을 입력해주지 않아도 자동으로 입력된 것을 확인할 수 있었다.
다른 값을 하나 더 넣었을 때 mem_no 가 2로 자동으로 증가하는 것도 확인하였다.
-
앞서 본 예시들은 열 정의와 동시에 제약 조건을 걸어주었지만
제약 조건을 열 정의 후에 별도로 지정하는 방법도 존재한다.
CREATE TABLE tb_member (
mem_no INT AUTO_INCREMENT,
mem_id VARCHAR(20),
mem_pass VARCHAR(20) NOT NULL,
mem_name VARCHAR(15) NOT NULL,
enroll_date DATE DEFAULT CURDATE()
CONSTRAINT PRIMARY KEY (mem_no, mem_id)
UNIQUE (mem_id)
);
또한, 두 열을 합쳐서 하나의 기본 키를 PRIMARY KEY로 지정하고 싶은 경우,
위 SQL문처럼 적어줘야 하며 각각 열 선언 후 바로 PRIMARY KEY를 선언하는 경우에는 에러가 발생한다.
(위 SQL문은 그냥 예시일 뿐 기본 키를 2개로 하는 경우는 많이 존재하지 않는다.)
-
또한, CONSTRAINT도 생략이 가능하며
UNIQUE 제약 조건도 동일하다.
UNIQUE 제약 조건에 이름을 주는 것도 가능하다.
-- CONSTRAINT 이름 UNIQUE 열 이름
CONSTRAINT uq_tb_member_mem_id UNIQUE (mem_id)
위와 같은 SQL문을 사용하면 된다.
또한, UNIQUE 열도 위의 PRIMARY KEY와 같이 여러 개의 열을 묶어서 하나의 제약 조건으로도 생성 가능하다.
-
FOREIGN KEY 제약 조건
두 테이블 사이의 관계를 설정하는 키 (외래 키)
두 테이블의 관계를 설정하면 하나의 테이블이 다른 테이블에 의존하게 된다.
외래 키가 있는 테이블에 데이터를 입력할 때는 기준 테이블에 이미 데이터가 존재해야 한다.
(열의 이름은 달라도 되지만 데이터 유형은 같아야 함)
참조하는 테이블을 부모 테이블이라고 함
-- 외래키 선언
CREATE TABLE 테이블명 (
...
열 이름 (동일한 데이터 유형) REFERENCES (참조할 테이블명)(참조할 열 이름)
);
이를 이용하여 테이블을 만들어보자.
-- 기준 테이블 생성
CREATE TABLE tb_member_grade (
grade_code VARCHAR(10) PRIMARY KEY,
grade_name VARCHAR(10) NOT NULL
);
INSERT INTO tb_member_grade VALUES ('vip', 'VIP 회원');
INSERT INTO tb_member_grade VALUES ('gold', '골드 회원');
INSERT INTO tb_member_grade VALUES ('silver', '실버 회원');
-- 외래 키 테이블 생성
DROP TABLE tb_member;
CREATE TABLE tb_member (
mem_no INT AUTO_INCREMENT PRIMARY KEY,
mem_id VARCHAR(20) NOT NULL UNIQUE,
mem_pass VARCHAR(20) NOT NULL,
mem_name VARCHAR(15) NOT NULL,
-- grade_code VARCHAR(10) REFERENCES tb_member_grade
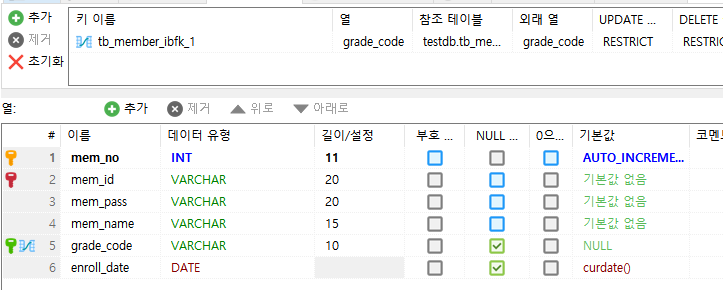
grade_code VARCHAR(10) REFERENCES tb_member_grade(grade_code),
enroll_date DATE DEFAULT CURDATE()
);
INSERT INTO tb_member(mem_id, mem_pass, mem_name, grade_code)
VALUES ('user1', '1234', '홍길동', 'vip');
-- tb_member_grade 테이블의 grade_code 열에
-- bronze라는 값이 없어서 외래 키 제약 조건에 위배되어 에러가 발생
INSERT INTO tb_member(mem_id, mem_pass, mem_name, grade_code)
VALUES ('user2', '1234', '이몽룡', 'bronze');
-- grade_code 열에 NULL 값은 삽입 가능
INSERT INTO tb_member(mem_id, mem_pass, mem_name, grade_code)
VALUES ('user2', '1234', '이몽룡', NULL);
만약 생성할 때 참조할 열을 안 적고 테이블 명만 적는다면 기본적으로 해당 테이블의 PRIMARY KEY를 참조한다.
또한, 값을 삽입할 때 참조하는 테이블에 존재하는 열의 값만 올 수 있다.
만약 참조하는 테이블에 존재하지 않는 값을 삽입하려고 했을 때 외래 키 제약 조건에 위배되어 에러가 발생한다.
단, NULL 값은 들어갈 수 있다.
-
값을 삭제해 보자!
-- tb_member_grade 테이블에서 grade_code가 VIP인 데이터 삭제
DELETE
FROM tb_member_grade
WHERE grade_code = 'vip';
위 코드를 실행하였을 때, 값이 삭제가 되지 않는다. 왜일까?
왜냐하면 vip는 참조하는 값이 있기 때문에 삭제가 되지 않는다.
반면에 참조하는 값이 없는 silver는 삭제가 되었다.
즉, 삭제하고자 하는 데이터가 참조하는 값이 있을 때 삭제가 진행되지 않는다.
테이블 정보에 들어가서 외래 키 부분을 살펴보자.

DELETE 될 때의 값을 'SET NULL'로 변경해 준 뒤 데이터 삭제를 진행하면 아래와 같은 결과를 얻을 수 있다.

위와 같이 값이 NULL 값으로 변한다.
즉, SET NULL 값으로 설정해 두고 데이터 삭제를 진행하면 참조된 값이 있어도 값이 삭제되며 NULL 값으로 변한다.
-
이번엔 CASCADE로 바꾸어 진행해 보자.

CASCADE로 변경하고 삭제를 진행하면 아래와 같은 결과를 받을 수 있다.

CASCADE는 참조하고 있는 값의 행을 다 지워버린다.
* 즉,
RESTRICT 상태로 두고 값을 삭제하면 값이 삭제되지 않는다.
NOT NULL 상태로 두고 값을 삭제하면 값이 삭제되어 NULL 값으로 변한다.
CASCADE 상태로 두고 값을 삭제하면 삭제하고자 하는 값의 행을 다 지워버린다.
-
값을 업데이트해 보자.
RESTRICT 상태로 두고 진행하면 값이 변경되지 않는다.
CASCADE 상태로 두고 UPDATE를 진행하면, 참조하는 테이블의 값과 참조하는 테이블의 값 모두 변경된다.
SET NULL 상태로 두고 UPDATE를 진행하면 참조하던 테이블의 값은 바뀌지만, 자식 테이블의 값은 참조하는 값이 없으므로 NULL 값으로 변경된다.
* 그러나 모두 일반적인 RESTRICT 상태로 두고 사용한다. (기본)
이것들을 테이블 생성 시에 설정하려면 아래와 같이 외래키 참조할 때 써주면 된다.
CREATE TABLE tb_member (
mem_no INT AUTO_INCREMENT PRIMARY KEY,
mem_id VARCHAR(20) NOT NULL UNIQUE,
mem_pass VARCHAR(20) NOT NULL,
mem_name VARCHAR(15) NOT NULL,
grade_code VARCHAR(10) REFERENCES tb_member_grade(grade_code) ON DELETE CASCADE ON UPDATE CASCADE,
enroll_date DATE DEFAULT CURDATE()
);
(위와 같이 쓰면 CASCADE 상태로 생성된다.)
원래 만들어진 테이블에 대해서 변경할 때는 툴을 이용하면 간단하다.
-
CHECK 제약 조건
열에 입력되는 데이터를 점검하는 기능
CHECK 제약 조건을 설정한 후에는 제약 조건에 위배되는 값은 열에 입력되지 않는다.
DROP TABLE tb_member;
CREATE TABLE tb_member (
mem_no INT AUTO_INCREMENT PRIMARY KEY,
mem_id VARCHAR(20) NOT NULL UNIQUE,
mem_pass VARCHAR(20) NOT NULL,
mem_name VARCHAR(15) NOT NULL,
gender CHAR(2),
age TINYINT,
grade_code VARCHAR(10) REFERENCES tb_member_grade,
enroll_date DATE DEFAULT CURDATE()
);
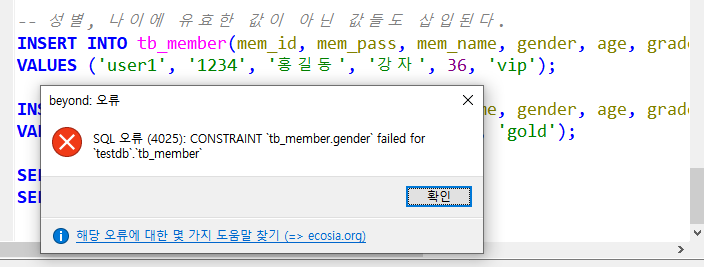
INSERT INTO tb_member(mem_id, mem_pass, mem_name, gender, age, grade_code)
VALUES ('user1', '1234', '홍길동', '강자', 36, 'vip');
INSERT INTO tb_member(mem_id, mem_pass, mem_name, gender, age, grade_code)
VALUES ('user2', '1234', '성춘향', '여자', -36, 'gold');
아무런 조건 없이 테이블을 만들었을 때 값이 어떻게 삽입되는지 확인해 보자.

테이블 입장에서는 별도의 제약 조건이 없기 때문에 값이 제대로 삽입된다.
그러나 논리적으로 알맞지 않은 값들이 존재한다.
이런 경우를 방지하기 위해서 테이블 생성 시에 CHECK 제약 조건을 거는 것이다.
성별에는 '남자' 또는 '여자'만 삽입되도록, 나이에는 0 ~ 150 사이의 값만 들어가도록 제약을 줘보자.
-- 나머지는 위 코드와 동일
gender CHAR(2) CHECK(gender IN ('남자', '여자')),
age TINYINT,
...
CONSTRAINT ck_tb_member_age CHECK(age BETWEEN 0 and 100)
...
아래와 같이 제약 조건이 설정된 것을 확인할 수 있다.

위와 같은 값으로 값들을 삽입 수행하면 아래와 같이 제약 조건 위배로 인한 에러가 발생한다.
정상적인 값을 삽입할 경우에만 아래와 같이 테이블에 값이 저장된다.

점점 복잡해지고 있어서 머리가 아프다 ㅎㅎ
그치만 열심히 SQL문 조합해서 올바른 결과를 출력해 냈을 땐 정말 뿌듯하다 ~_~
'일일 정리' 카테고리의 다른 글
| 240524 MariaDB(7) - 인덱스/스토어드 프로시져/트리거 (0) | 2024.05.26 |
|---|---|
| 240523 MariaDB(6) - 테이블 수정/뷰 (0) | 2024.05.24 |
| 240521 MariaDB(4) - 조인/UNION 연산자/인라인 뷰 (0) | 2024.05.21 |
| 240520 MariaDB(3) - 함수/조인/UNION 연산자 (0) | 2024.05.20 |
| 240517 MariaDB(2) - SQL/데이터 변경/데이터 형식/함수 (0) | 2024.05.17 |