월요일 화이팅 ~.~
(이어서..)
문자열 함수
CONCAT
문자열을 이어주는 함수
CONCAT_WS 함수는 구분자와 함께 문자열을 이어준다.
CONCAT(문자열1, 문자열2, ...)
CONCAT_WS(구분자, 문자열1, 문자열2, ...)
ELT()
위치 번째에 해당하는 문자열을 반환한다.
ELT(위치, 문자열1, 문자열2, ...)
FIELD()
찾을 문자열의 위치를 찾아서 반환한다.
매치되는 문자열이 없으면 0을 반환한다.
FIELD(찾을 문자열, 문자열1, 문자열2, ...)
FIND_IN_SET()
찾을 문자열을 문자열 리스트에서 찾아서 위치를 반환한다.
문자열 리스트는 콤마로 구분되어 있어야 하며 공백은 없어야 한다.
FIND_IN_SET(찾을 문자열, 문자열 리스트)
INSTR() << 얘를 좀 많이 쓸 듯
기존 문자열에서 부분 문자열을 찾아서 그 시작 위치를 반환한다.
INSTR(기존 문자열, 부분 문자열)
LOCATE()
INSTR() 함수와 동일하지만 파라미터의 순서가 반대로 되어있다.
LOCATE() 함수와 POSITION() 함수는 동일하다.
LOCATE(부분 문자열, 기존 문자열)
INSTR()의 예제만 살펴보겠다.
-- employee 테이블에서 이메일의 @의 위치값 출력
SELECT email, INSTR(email, '@')
FROM employee;

INSERT()
기존 문자열의 위치부터 길이만큼을 지우고 삽입할 문자열을 끼워 넣는다.
정한 위치에서부터 문자열 사이에 끼워 넣는 게 아니고 대체된다. (난 처음에 끼워 넣는 건 줄 알았다.. )
INSERT(기존 문자열, 위치, 길이, 삽입할 문자열)
만약 삽입할 문자열의 길이가 정해둔 길이보다 길더라도 문자열은 다 삽입된다.
LEFT(문자열, 길이)
왼쪽에서 문자열의 길이만큼 반환한다.
RIGHT(문자열, 길이)
오른쪽에서 문자열의 길이만큼 반환한다.
-- 이메일에서 @ 앞까지만 잘라내기
SELECT emp_name, LEFT(email, INSTR(email, '@') - 1)
FROM employee

위와 같이 여러 함수들을 조합해서 사용할 수도 있다.
UPPER(문자열)
소문자 > 대문자 변경 함수이다.
LOWER(문자열)
대문자 > 소문자 변경 함수이다.
LPAD(문자열, 길이, 채울 문자열)
문자열을 길이만큼 왼쪽을 늘린 후에, 빈 곳을 채울 문자열로 채운다.
RPAD(문자열, 길이, 채울 문자열)
문자열을 길이만큼 오른쪽을 늘린 후에, 빈 곳을 채울 문자열로 채운다.
* 기존에 있던 문자열을 포함해서 총 길이가 지정한 길이만큼 됨
아래와 같이 응용할 수 있다.
-- employee 테이블에서 사원명, 주민등록번호 출력
SELECT emp_name,
RPAD(LPAD(emp_no, 8), 14, '*')
FROM employee;

위와 같이 두 함수를 중첩해서 사용할 수도 있다.
LPAD를 통해서 성별 코드 앞까지 자른 다음, 다시 RPAD를 통해서 길이를 늘려 * 표시로 채워준다.
LTRIM(문자열)
문자열의 왼쪽 공백을 제거한다.
RTRIM(문자열)
문자열의 오른쪽 공백을 제거한다.
* LTRIM()과 RTRIM() 모두 중간의 공백은 제거되지 않는다.
TRIM(문자열)
문자열의 앞, 뒤 공백 모두 제거한다.
TRIM(방향 자를 문자열 FROM 문자열)
방향을 지정해서 자를 문자열을 제거할 수 있다.
방향은 LEADING(앞), TRAILING(뒤), BOTH(양쪽)으로 지정한다.
REPEAT(문자열, 횟수)
문자열을 횟수만큼 반복한다.
SPACE(길이)
길이만큼의 공백을 반환한다.
REVERSE(문자열)
문자열의 순서를 거꾸로 만든다.
REPLACE(문자열, 원래 문자열, 바꿀 문자열)
문자열에서 원래 문자열을 찾아서 바꿀 문자열로 바꿔준다.
예시로는 아래와 같다.
-- employee 테이블에서 이메일의 kh.or.kr을 naver.com으로 변경
SELECT emp_name,
REPLACE(email, 'kh.or.kr', 'naver.com')
FROM employee;

'kh.or.kr'이던 이메일 뒷부분이 'naver.com'으로 변경된 것을 확인할 수 있다.
또한, 바꿀 문자열에 아무것도 주지 않게 되면 ('') 원래 문자열은 사라진다.
SUBSTRING(문자열, 시작 위치, 길이)
SUBSTRING(문자열 FROM 시작위치 FOR 길이)
시작 위치부터 길이만큼 문자를 반환한다.
길이가 생략되면 문자열의 끝까지 반환한다.
* 시작 위치가 - (음수값) 일 때에는 문자열을 뒤에서부터 자른다.
이런 식으로 응용도 할 수 있다.
-- employee 테이블에서 이름, 성별 조회
SELECT emp_name,
SUBSTRING(email, 1, INSTR(email, '@')-1) AS ID,
SUBSTRING(emp_no, 8, 1),
IF(SUBSTRING(emp_no, 8, 1) = 1, '남자', '여자') AS 'gender'
FROM employee;

SUBSTRING_INDEX(문자열, 구분자, 횟수)
문자열에서 구분자가 왼쪽부터 횟수번째에 나오면 그 이후의 오른쪽은 버린다.
횟수가 음수이면 오른쪽부터 세고 왼쪽을 버린다.
-- employee 테이블에서 아이디 조회
SELECT SUBSTRING_INDEX(email, '@', 1)
FROM employee;
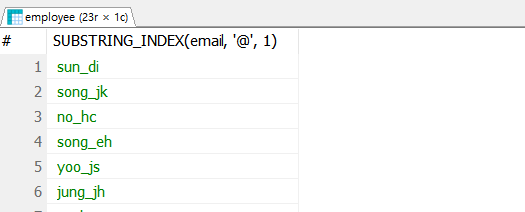
이메일 @ 뒷부분을 간단하게 지울 수도 있다.
-
수학 함수
간단하게 몇 가지만 진행하였다.
ABS(숫자)
숫자의 절댓값을 계산한다.
CEILING(숫자)
숫자를 올림 하여 반환한다.
CEILING()과 CEIL()은 동일한 함수이다.
FLOOR(숫자)
숫자를 내림하여 반환한다.
ROUND(숫자)
숫자를 반올림을 반환한다.
ROUND 함수에서 인자를 1개 받는 경우와 2개 받는 경우가 있다.
1개의 경우에는 소수숫점 첫째 자리에서 반올림을 진행하고,
2개의 경우에는 (숫자, 소수점 위치)를 입력받아 지정한 소수점 위치를 기준으로 반올림을 진행한다.
또한, 소수점 위치에 음수로 표현했을 때 소수점 앞의 N번째 자리에서 반올림한다.
TRUNCATE(숫자, 정수)
숫자를 소수점을 기준으로 정수 위치까지 구하고 나머지는 버린다.
MOD(숫자1, 숫자2) = 숫자 1 % 숫자 2
숫자 1을 숫자 2로 나눈 나머지 값을 구한다.
POW(숫자)
숫자의 거듭제곱 값을 반환한다.
SQRT(숫자)
숫자의 제곱근을 반환한다.
RAND()
0 이상 1 미만의 실수를 구한다.
만약, RAND() * 100을 하면, 0에서 100 미만 값을 추출하게 된다.

공식은 이거 말고도 여러 가지가 있다.
SIGN(숫자)
숫자가 양수, 0, 음수인지를 구한다.
결과는 1, 0, -1 중에 하나를 반환한다. (1 양수, 0, -1 음수)
-
날짜 및 시간 함수
ADDDATE(날짜, 차이) / SUBDATE(날짜, 차이)
날짜를 기준으로 차이를 더한/뺀 날짜를 반환한다.
ADDTIME(날짜/시간, 시간) / SUBTIME(날짜/시간, 시간)
날짜/시간을 기준으로 시간을 더한/뺀 결과를 반환한다.
CURDATE()
현재 연-월-일을 조회하는 함수이다.
CURTIME()
현재 시:분:초를 조회하는 함수이다.
NOW() / SYSDATE()
현재 연-월-일 시:분:초를 조회하는 함수이다.
DATEDIFF(날짜 1, 날짜 2) / TIMEDIFF(시간 1, 시간 2)
날짜 1 - 날짜 2의 일수 결과 / 시간 1- 시간 2 차이 결과를 반환한다.
아래는 예시이다.
-- employee 테이블에서 직원명, 입사일, 근무일수를 조회
SELECT emp_name,
hire_date,
DATEDIFF(CURDATE(), hire_date) AS '근무일수'
FROM employee;

DAYOFWEEK(날짜)
날짜의 요일 (1:일, 2:월, ... 7:토)을 반환한다.
MONTHNAME(날짜)
날짜의 월의 이름을 반환한다.
DAYOFYEAR(날짜)
날짜가 1년 중 몇 번째 날짜 인지를 반환한다.
LAST_DAY(날짜)
주어진 날짜의 마지막 날짜를 구한다.
MAKEDATE(연도, 정수)
연도에서 정수만큼 지난 날짜를 구한다.
MAKETIME(정수, 정수, 정수)
시, 분, 초를 이용해서 시:분:초 의 TIME 형식을 만든다.
-
시스템 정보 함수
USER()
현재 사용자를 반환한다.
DATABASE()
현재 선택된 데이터베이스 이름을 반환한다.
윈도우 함수
순위 함수
데이터를 순서대로 번호 매기거나 특정 조건에 따라 순위(등수)를 매길 수 있다.
순위 윈도우 함수에는 ROW_NUMBER(), RANK(), DENSE_RANK(), NTILE() 등의 함수가 있다.
예시는 다음과 같다.
순위 함수 뒤에는 OVER(정렬 조건) 절을 함께 써준다.

ROW_NUMBER() 함수가 height를 기준으로 정렬해 준다.
그리고 보면 2번 3번이 같은 키임에도 불구하고 2,3으로 정렬이 되었는데 이럴 때에는 또 다른 조건을 주면 된다. (이름순 등)
또 다른 예시를 살펴보자.

PARTITION BY는 열의 이름으로 그룹을 만든다는 함수이다.
PARTITION BY를 통해서 지역별로 나뉜 그룹에서 키 순서대로 번호를 매긴다.
RANK() 함수의 예시를 보겠다.

RANK() 함수를 사용했더니 동일한 순위 이후의 등수를 동일한 인원수만큼 건너뛰고 증가하였다.
반면에 DENSE_RANK() 함수를 사용했을 때에는 동일한 순위 이후에 인원수에 상관없이 +1 증가한다.
NTILE() 함수는 인자로 숫자를 받는데, 전체 열을 OVER() 절의 기준에 맞게 나열한 후에 숫자만큼의 그룹으로 나눈다.

-
분석 함수
현재 행의 이전 행이나 다음 행의 데이터를 참조하거나, 윈도우의 첫 값이나 마지막 값을 가져올 수 있다.
LEAD(), LAG(), FIRST_VALUE(), LAST_VALUE(), CUME_DIST() 등이 있다.
근데 잘 사용할 일은 없을 것이다...
간단한 예시들 몇 가지만 보겠다.
-- 키 순서대로 정렬 후 다음 사람과 키 차이를 조회
SELECT NAME,
addr,
height,
height - LEAD(height, 1) OVER (ORDER BY height DESC)
FROM usertbl;
결과는 아래와 같다.

이번에는 이전 사람과의 키 조회를 해보겠다.
SELECT NAME,
addr,
height,
height - LAG(height, 1) OVER (ORDER BY height DESC)
FROM usertbl;
결과는 아래와 같다.

이전 사람이 존재하지 않는 경우 값이 NULL로 뜬다.
조인과 UNION 연산자
조인
두 개 이상의 테이블을 서로 묶어서 하나의 결과 집합으로 만들어 내는 것을 말한다.
내부 조인
조인 중에 가장 많이 사용되는 조인, 일반적으로 조인이라고 얘기하는 것이 내부 조인이다.
FROM 절 다음에 INNER JOIN 구문을 통해 조인에 사용할 테이블을 기술하고 ON 절에 조인 조건을 작성한다.
SELECT *
FROM employees e
INNER JOIN departments d ON e.dept_no = d.dept_no;
테이블 이름 다음에 쓰는 것을 테이블 별칭이라고 말한다.
테이블 내의 같은 열의 이름을 구분하기 위해서 사용한다.
조인의 간단한 예시를 풀어보자!
-- 각 사원들의 사번, 직원명, 부서 코드, 부서명 조회
-- 사번, 직원명, 부서코드 -> employee 테이블
-- 부서명 > department 테이블
SELECT emp_id,
emp_name,
dept_code,
dept_title
FROM employee
INNER JOIN department ON dept_code = dept_id;
다음 예시를 살펴보자.
-- 방법1)
-- 각 사원들의 사번, 직원명, 직급코드, 직급명 조회
SELECT e.emp_id,
e.emp_name,
j.job_code,
j.job_name
FROM employee e
INNER JOIN job j ON e.job_code = j.job_code
WHERE j.job_name = '대리';
-- 방법2
-- 또는
INNER JOIN job j
WEHRE e.job_code = j.job_code;
-- 위와 같이 줘도 되지만,
-- 되도록이면 JOIN 조건을 ON 뒤에, 검색 조건을 WHERE 절에 적어주도록 한다.
-- 방법3) 자연조인
-- 조건을 정해주지 않아도 같은 열끼리 알아서 조인해줌
SELECT emp_id,
emp_name,
job_code,
job_name
FROM employee
NATURAL JOIN job;
-- 그러나 이 방법은 같은 이름의 열이 있을 때에 내가 원하는대로 동작하지 않을 수 있기 때문에
-- 거의 사용하지 않는 방법이다.
위와 같이 조인하고자 하는 열의 이름이 동일할 때 테이블의 별칭을 정해서 구분해주어야 한다.
SELECT 부분에 가져오는 값들은 아무거나 가져와도 상관없다. 그러나 맞춰 주면 좋다!
(테이블의 이름을 그대로 붙여도 되지만 별칭을 붙이면 더 간결하고 보기 좋다.)
또는 이후의 코드로 사용해도 되지만,
표준에서는 JOIN 조건은 ON 절 뒤에, 검색 조건은 WHERE 절에 적어주는 것을 권장한다.
결과는 아래와 같다.

강사님께서 주신 실습 문제 4가지!
Q1. usertbl 테이블과 buytbl 테이블을 조인하여 JYP라는 아이디를 가진 회원의 이름, 주소, 연락처, 주문 상품을 조회
SELECT u.NAME AS '이름',
u.addr AS '주소',
CONCAT(u.mobile1, u.mobile2) AS '연락처',
b.prodName AS '주문 상품'
FROM usertbl u
INNER JOIN buytbl b ON u.userID = b.userID
WHERE u.userID = 'JYP';

Q2. employee 테이블과 department 테이블을 조인하여 보너스를 받는 사원들의 사번, 직원명, 보너스, 부서명을 조회
SELECT e.emp_id AS '사번',
e.emp_name AS '직원명',
e.bonus AS '보너스',
d.dept_title AS '부서명'
FROM employee e
INNER JOIN department d ON e.dept_code = d.dept_id
WHERE e.bonus IS NOT NULL;

보너스를 받는 직원 8명만 출력되었다.
NULL 값은 반드시 IS NULL / IS NOT NULL 사용 !!!
Q3. employee 테이블과 department 테이블을 조인하여 인사관리부가 아닌 사원들의 직원명, 부서명, 급여를 조회
SELECT e.emp_name AS '직원명',
d.dept_title AS '부서명',
e.salary AS '급여'
FROM employee e
INNER JOIN department d ON d.dept_id = e.dept_code
WHERE dept_title != '인사관리부';

(너무 길어서 아래 결과는 생략하였다.)
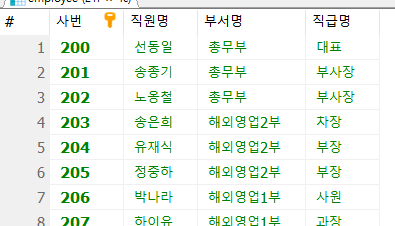
Q4. employee 테이블과 department 테이블, job 테이블을 조인하여 사번, 직원명, 부서명, 직급명 조회
SELECT e.emp_id AS '사번',
e.emp_name AS '직원명',
d.dept_title AS '부서명',
j.job_name AS '직급명'
FROM employee e
INNER JOIN department d ON d.dept_id = e.dept_code
INNER JOIN job j ON j.job_code = e.job_code;
조인은 위에서부터 진행된다.
employee 테이블과 department 테이블이 조인된 결과를 가지고
job 테이블과 한 번 더 조인한다.
* 순서가 잘못되면 조인 조건이 잘못될 수도 있다.
실습 조건을 통해서 주의할 점은
조인 조건 주는 것과 WHERE절의 검색 조건 주는 것을 혼동하지 말 것 ~!
'일일 정리' 카테고리의 다른 글
| 240522 MariaDB(5) - DB 모델링/테이블/제약 조건 (0) | 2024.05.22 |
|---|---|
| 240521 MariaDB(4) - 조인/UNION 연산자/인라인 뷰 (0) | 2024.05.21 |
| 240517 MariaDB(2) - SQL/데이터 변경/데이터 형식/함수 (0) | 2024.05.17 |
| 240516 MariaDB (1) - MariaDB 설치/사용자 생성/권한 부여/SQL (0) | 2024.05.16 |
| 240514 리눅스(2) - Vim/Vim 명령어/파일 접근 권한 (0) | 2024.05.15 |