240517 MariaDB(2) - SQL/데이터 변경/데이터 형식/함수
첫 주의 마지막 날 ~.~ !!
또 정신없이 일어나서 수업 듣는다.
(어제 내용에 이어서...)
GROUP BY
여러 개의 값들을 하나의 그룹으로 묶어서 처리할 목적으로 사용
WHERE 절이 있다면 WHERE 절과 ORDER BY 절 사이에 위치
별칭 사용 불가
집계 함수(SUM, AVG, MIN, MAX)를 이용해 하나 이상의 행을 그룹으로 묶어 연산 가능
간단한 예제를 살펴보자.


같은 그룹끼리 묶어준다.
결과가 중복 제거 한 것과 동일하지만 전혀 다르다는 것을 알아야 한다.
그룹에 묶인 행의 수를 세어주는 COUNT() 함수(조회된 행을 반환)를 사용하면
행의 수가 올바르게 세어지는 것을 알 수 있고,
DISTINCT를 사용했을 때의 COUNT() 함수는 전체 행 중에 카운트해서 출력한다.
다른 DBMS의 경우였다면 에러가 났을 것이다.
또 다른 예시를 살펴보자.

실습할 때 GROUP BY 절이 아니라 ORDER BY 먼저 썼더니 에러가 났다.
실행 우선순위에 대해서는 조금 아래에서 정리하겠다.
집계 함수를 이용한 또 다른 예시를 살펴보자.
사용자 별로 구매한 물품 개수의 합계를 조회해 보자.

간단하다!
정렬이 필요하면 아래에 ORDER BY 절을 한 번 써주면 된다.
다음 예시는 가장 큰 키와 작은 키를 출력하는 것이다.
출력과 동시에 회원의 이름도 함께 출력해 보자.
이때는 서브 쿼리라는 걸 다뤄야 하는데,
서브 쿼리는 쿼리 안에 쿼리를 집어넣는 것이다.
반드시 서브 쿼리는 괄호로 감싸주어야 하며, 서브 쿼리 안에 세미콜론을 붙이면 안 된다.
서브 쿼리를 감싸주고 있는 것을 메인 쿼리라고 한다.
서브 쿼리가 먼저 수행이 되고 이 결과를 가지고 메인 쿼리가 실행이 된다.
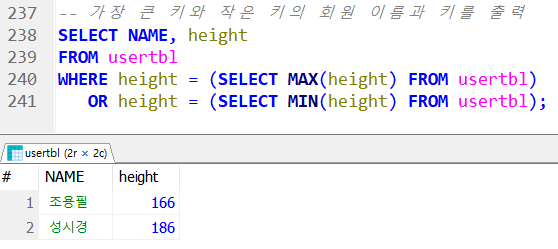
위와 같이 결과가 출력되는 것을 알 수 있다.
조금 더 자세한 내용은 뒤에서 다시 한번 정리하겠다.
즉, 집계 함수를 정리해 보면
합계 SUM(X)
평균 AVG(X)
최댓값 MAX(X)
최솟값 MIN(X)
로 사용이 가능하다.
(자잘한 예시들은 넣지 않겠다.)
다 섞어서 하는 예시 !!!
employee 테이블에서 부서별 사원의 수, 보너스를 받는 사원의 수, 급여의 합,
평균 급여, 최고 급여, 최저 급여를 조회 (부서별 내림차순 정렬)
SELECT dept_code AS '부서코드',
COUNT(*) AS '부서별 사원 수',
COUNT(bonus) AS '보너스를 받는 사원 수',
SUM(salary) AS '급여의 합',
AVG(salary) AS '평균 급여',
MAX(salary) AS '최고 급여',
MIN(salary) AS '최저 급여
FROM employee
GROUP BY dept_code
ORDER BY dept_code DESC;
할 때 잘못 생각해서 부서별 사원 수에서 COUNT(dept_code)로 썼었다.
그랬더니 dept_code가 NULL 값인 사원들은 카운트가 되지 않아서 당황했었는데
COUNT(*)를 해주면 되는 것이었다.

위와 같이 결과가 나오는 것을 확인할 수 있었다!
또한, 평균을 구할 때 FLOOR는 소수점 아래를 다 버리는 명령어이고
만약 반올림 하려면 ROUND를 쓰면 된다.
HAVING
집계 함수에 대해서 조건을 제한한다.
실습을 진행해보자!
-- 총 구매액이 1000 이상인 회원의 아이디, 구매 금액을 조회
SELECT userid, SUM(price * amount)
FROM buytbl
-- 집계 함수의 결과를 WHERE 절에서 조건으로 사용할 수 없다.
-- WHERE SUM(price * amount) >= 1000
GROUP BY userid
HAVING SUM(price * amount) >= 1000;

위와 같은 결과가 정상적으로 나오는 것을 확인했다.
아, HAVING 절은 GROUP BY 절 밑에 사용해야 한다.
그렇다면 왜 WHERE 절은 오류가 날까?
>>
-
강사님이 내주신 실습 문제 4가지!
Q1. employee 테이블에서 부서별로 급여가 300만 원 이상인 직원의 평균 급여를 조회
SELECT dept_code,
FLOOR(AVG(salary))
FROM employee
WHERE salary >= 3000000
GROUP BY dept_code;
근데 자꾸 끝에 세미콜론 붙이는 거 까먹음.. ㅠㅠ
그리고 바로 이전에 HAVING 절 배우고 왔다 보니까 HAVING 절로 어찌어찌해보려고 했던..
생각을 좀 하고 코딩 하자 - _ -
Q2. employee 테이블에서 부서별 평균 급여가 300만 원 이상인 부서 코드, 평균 급여를 조회
SELECT dept_code,
FLOOR(AVG(salary))
FROM employee
GROUP BY dept_code
HAVING AVG(salary) >= 3000000;
Q3. employee 테이블에서 직업별 총급여의 합이 10,000,000 이상인 직급만 조회
SELECT job_code, SUM(salary)
FROM employee
GROUP BY job_code
HAVING SUM(salary) >= 10000000
Q4. employee 테이블에서 부서별 보너스를 받는 사원이 없는 부서만 조회
SELECT dept_code, COUNT(bonus)
FROM employee
GROUP BY dept_code
HAVING COUNT(bonus) = 0
ORDER BY dept_code DESC;
ㅎ 가볍다!! (아님)
-
실행 우선순위 정리
여러 줄 주석 /* */
SELECT 문이 실행되는 순서
5: SELECT
1: FROM
2: WHERE
3: GROUP BY
4: HAVING
6: ORDER BY
7: LIMIT
ORDER BY 절은 항상 마지막에 실행된다!
근데, ORDER BY 보다 더 늦게 실행되는 것은 LIMIT 절이다.
데이터 변경
INSERT
테이블에 데이터를 삽입
INSERT INTO 테이블 이름(열 이름), VALUES('값1', '값2', ...);
열 이름은 생략도 가능하다.
단, 열의 순서대로 값이 삽입되므로 순서에 주의할 것
INSERT INTO 테이블이름 VALUES ('값1', '값2', ...), ('값3', '값4' ...)
위는 여러 행에 값을 삽입할 때이다.
VALUES 다음에 괄호 하나당 행 하나의 값들이다.
INSERT INTO 테이블1
SELECT *
FROM 테이블2
다른 테이블에서 데이터를 가져와서 대량으로 입력도 가능하다.
실습을 진행해보자!
INSERT INTO usertbl(userid, NAME, birthYear, addr)
VALUES ('hong123', '홍길동', 1995, '서울');
근데 제발 마지막에 세미콜론 좀 붙여라 ㅠㅠ 자꾸 까먹네..
그러고 나서 테이블을 확인해보면

추가된 것을 확인할 수 있다!
열을 지정해서 추가하다 보니 지정되지 않은 열에는 NULL 값이 들어간다.
또한, 열의 순서에 따라 데이터 타입이 맞지 않은 경우에 에러가 발생한다.

또한, 위처럼 노란 키, 기본 키가 지정되어 있는 열에 값에 NULL 값이 입력될 수 없어서 에러가 뜬다.

테이블 지정 후 열을 나열해주지 않으면,
테이블에 있는 모든 열에 대한 데이터를 추가해주어야 한다.
? NULL 값으로 안 들어가나요?
그런데 왜 INSERT 했을 때 순서가 마지막이 아니라 랜덤인가?
INSERT 했을 때 데이터를 입력했다고 입력 순서대로 들어가는 것이 아니라
기본키 값을 기준으로 오름차순으로 정렬한다.
새로운 예시를 위해서 테이블 새로 하나 복사 해주었다.
-- 테이블 복사 / 단, 키는 복사 안됨
CREATE TABLE emp_copy (
SELECT *
FROM employee
WHERE 1 = 0 -- 모든 행에 대해 거짓이기 때문에 데이터 조회가 안됨
);
이후 employee에서 조건을 주어 INSERT를 진행한다.

위와 같이 SELECT에 해당하는 결과들만 테이블에 삽입되었다.

위와 같이 코드를 썼더니 에러가 떴다.
앞서 본 에러와 똑같다.
열을 지정해주지 않았을 때, 조회 개수와 삽입하려고 하는 테이블의 열의 개수가 맞지 않아서 그렇다.
이럴 경우에는 삽입하려는 테이블 뒤에 열을 지정해 주어야 한다.
-
UPDATE
기존에 입력되어 있는 값을 변경할 때 사용한다.
WHERE 절은 생략이 가능하지만 WHERE 절을 생략하면 테이블 전체의 행이 변경된다.
UPDATE 테이블
SET 변경할 열 이름1 = '값1',
변경할 열 이름2 = '값2'
WHERE 열 = '값3';
usertbl 테이블에서 userid가 hong123인 회원의 이름을 고길동으로 변경해보자.
UPDATE usertbl
SET NAME = '고길동'
WHERE userid = 'hong123';
그럼 아래와 같이 홍길동이 고길동으로 변경되는 것을 확인할 수 있다.
또한, WHERE 절에 조건을 줄 때 중복된 값이 없는 열을 지정해 주는 것이 좋다. (EX. 기본키)

-
DELETE
행 단위로 데이터를 삭제할 때 사용한다.
WHERE 절은 생략이 가능하지만 WHERE 절을 생략하면 테이블 전체의 행이 삭제된다.
만약 조건을 만족하는 결과 중 상위 몇 건만 사용하려면 LIMIT와 함께 사용한다.
-- 조건에 만족하는 행 삭제
DELETE FROM 테이블 WHERE 조건;
-- 테이블 삭제
DROP TABLE 테이블;
-- 테이블의 모든 데이터 삭제
TRUNCATE TABLE 테이블;
강사님의 꿀팁을 하나 받았다.
DELETE의 경우 다시 복구가 안 되기 때문에 엄청 주의해야 하는데,
그럴 때에는 삭제할 내용을 SELECT를 이용해서 삭제될 데이터의 조건을 적어 실행하여
데이터를 확인한 뒤, SELECT * 를 지우고 DELETE를 하는 방법이다.
다시 복구가 안된다는 점에서 여러 번 체크할 수 있어서 좋은 방법 중 하나인 것 같다.
아까 INSERT 실습 때 추가했던 인원들을 삭제시켜보자.
height가 NULL 인 회원들 중 상위 2명만 삭제해보자.
DELETE
FROM usertbl
WHERE height IS NULL
LIMIT 2;
위와 같이 실행하고
SELECT 문을 이용해서 확인하면 값이 올바르게 삭제된 것을 확인할 수 있었다.
SQL 문으로도 삭제가 가능하지만 테이블을 눌려 데이터에 들어가서 툴을 통해서도 삭제가 가능하다.
-
조건부 데이터 입력, 변경
기본적으로 기본 키(PK)가 중복된 경우 데이터가 입력되지 않는다. (행을 식별하기 위함)
만약, 중복된 기본 키를 입력하면 오류가 발생한다.
기본 키(PK)가 중복되더라도 오류를 발생하지 않고 무시하고 넘어가려면 아래와 같이 작성하면 된다.
INSERT IGNORE INTO 테이블 VALUES('값1', '값2', ...);
에러만 발생하고 값이 추가되진 않는다.
기본 키(PK)가 중복되지 않으면 INSERT를 실행하고,
기본 키(PK)가 중복되면 UPDATE를 실행하려면 아래와 같이 쓴다.
INSERT INTO 테이블 VALUES ('값1', '값2', ...)
ON DUPLICATE KEY UPDATE 행1 = '값1', 행2 = '값2';
만약 INSERT 실행을 위한 값이 테이블에 존재한다면 UPDATE를 수행하고,
INSERT 실행을 위한 값이 없다면 INSERT를 수행한다.
INSERT 역시 툴을 통해서 값들을 추가할 수 있다.
수정 시에 아래를 보면 수정된 쿼리를 볼 수 있다.
데이터 형식
숫자 데이터 형식
너무 많아서 생략 ~.~
문자 데이터 형식
VARCHAR(N)는 딱 데이터 크기만큼만 할당해서 씀 (정해진 길이보다 작아도)
담기는 데이터가 N보다 크면 에러가 날 수 있다.
효율적으로 운영할 수 있는 건 CHAR보다 VARCHAR인데 상황마다 다름
함수
형 변환 함수
형 변환 함수의 유형과 형식은 아래와 같다.
SELECT CAST(데이터 AS 형식);
SELECT CONVERT(데이터, 형식);
-- 세 자리마다 콤마 찍기 + 숫자번째 소수점까지만 출력하여 문자형 변환
SELECT FORMAT(데이터, 숫자);
-- birthYear 열의 데이터를 문자 데이터로 형변환
SELECT NAME,
CONVERT (birthYear, CHAR)
-- 문자 데이터를 숫자 데이터로 형변환
SELECT CONVERT('1000000', INT);
FROM usertbl;
문자형으로 변환되면 글씨가 초록색으로 변한다.
숫자 데이터로 변환되면 글씨가 파란색으로 변한다.
만약, 숫자 사이에 콤마가 있다면 이것은 숫자 데이터로 변환할 수 없다.
콤마를 제거하거나 REPLACE 함수를 통해서 문자를 찾아 빈문자로 대체시켜줘야 한다.
EX) SELECT CONVERT(REPLACE('1,000,000', ',',''), INT);
SELECT CAS(REPLACE('1,000,000', ',','') AS INT);
-
실습 문제
Q1. 아래의 쿼리가 정상적으로 연산되도록 쿼리문을 작성하시오.
SELECT '1,000,000' - '500,000';
>> 콤마 때문에 자동 변환을 못해줘서 제대로 된 계산이 안 됨
-- 1번
SELECT '1000000' - '5000000';
-- 2번 / REPLACE만 해도 됨
SELECT CONVERT(REPLACE('1000000', ',', ''), INT)
- CONVERT(REPLACE('500000', ',', ''), INT);
Q2. employee 테이블에서 emp_id를 숫자 형식으로 변환해서 조회
SELECT CONVERT(emp_id, INT), emp_name
FROM employee;
모든 형태로 변환이 가능한 것은 아니다.
INTEGER만 가능한 걸로..
-
문자 데이터를 날짜 데이터로 형변환
SELECT CAST('2024/05/17' AS DATE);
SELECT CONVERT('2024/05/17', DATE);
-- 날짜 사이에 /(슬래쉬), %(퍼센트), - 다 상관없이 세 개중 하나면 된다
숫자 데이터를 날짜 데이터로 형변환
SELECT CAST(20240517 AS DATE);
-- DATETIME은 년월일과 시간 정보까지 다 가지고 있다.
SELECT CAST(20240517154238 AS DATETIME);
SELECT CAST(223859 AS TIME);
모든 형태로의 데이터 변환이 가능한 것은 아니다.
-
제어 흐름 함수
-- IF()
-- 수식이 참/거짓 여부에 따라 답이 다르게 나오는 함수
IF(수식, 참, 거짓)
-- IFNULL() = NVL()
-- 수식1이 NULL이 아니면 수식1 반환, 수식1이 NULL이면 수식2 반환
IFNULL(수식1, 수식2)
-- NVL2()
-- 열에 값이 있으면 값1 출력, 값이 없으면 값2 출력
NVL2(열 이름, '값1', '값2')
-- NULLIF()
-- 수식 1과 2가 같으면 NULL을 반환하고, 다르면 수식1 반환
-- CASE문
SELECT CASE
WHEN 조건1 THEN '값1'
WHEn 조건2 THEN '값2'
WHEN 조건3 THEN '값3'
ELSE '값'
END;
MariaDB의 10.3 버전부터 NVL() 함수와 NVL2() 함수가 추가되었으며,
NVL() 함수는 IFNULL()과 동일하다.
-
예시 몇 가지
-- 고객별 전체 구매 개수의 합계가 10 이상이면 VIP 고객, 아니면 일반 고객
SELECT userid, SUM(amout),
IF(SUM(amout) >= 10, 'VIP 고객', '일반 고객')
FROM buytbl
GROUP BY userid
ORDER BY userid;
-- employee 테이블에서 보너스를 0.1 동결하여 직원명, 보너스율,
-- 동결된 보너스율, 보너스가 포함된 연봉 조회
SELECT emp_name,
IFNULL(bonus, 0),
NVL2(bonus, 0.1, 0),
(salary + (salary + NVL2(bonus, 0.1, 0))) * 12
FROm employee;
-- employee 테이블에서 직원명, 급여, 급여 등급(1~4) 조회
-- 급여가 500만원 초과일 경우 1등급
-- 급여가 500만원 이하 350만원 초과일 경우 2등급
-- 급여가 350만원 이하 200만원 초과일 경우 3등급
-- 그 외의 경우 4등급
SELECT emp_name,
salary,
CASE
WHEN salary > 5000000 THEN '1등급'
WHEN salary > 3500000 THEN '2등급'
WHEN salary > 2000000 THEN '3등급'
ELSE '4등급'
END AS 'grade'
FROM employee
ORDER BY salary DESC;
-
문자열 함수
ASCII(문자)
문자의 아스키코드를 반환하는 함수
CHAR(숫자)
아스키코드 값에 해당하는 문자를 반환하는 함수
BIT_LENGTH(문자열)
문자열에 할당된 bit의 크기를 반환하는 함수
CHAR_LENGTH(문자열)
문자열에 문자의 개수를 반환한다.
관련 함수들이 너무 많기 때문에 다 작성하지 않았음!
예시
MariaDB는 기본적으로 UTF-8 코드를 사용하기 때문에
영문은 1Byte를, 한글은 3Byte를 할당한다.
그래서 아래 예시처럼 똑같은 3글자이지만 출력되는 값이 다르다.


LENGTH는 1Byte * 3 = 3
BIT_LENGTH는 3 * 8bit = 24

LENGTH는 3Byte * 3 = 9
BIT_LENGTH는 9 * 8bit = 72
CHAR_LENGTH는 문자열의 문자 개수를 반환하는 것이기 때문에 따로 언급하지 않겠다.